
Robotics Simulation Infrastructure
First part of a blog series diving into the world of robotics simulation and machine learning


Simulation infrastructure is the tooling and code that quietly underpins much of the world’s public robotics benchmarks and research like SIMPLER, MolmoSpaces, and Libero. Without simulation, robotics progress would have stalled due to a lack of testing platforms before deployment or training systems for modern-day locomotion. Behind each creation of a simulation environment and simulation step is often hundreds of decisions that turns complex low-level physics and rendering engines into playgrounds. Modern simulation infrastructure is also increasingly intertwined with machine learning, making the stack far more end-to-end.
But what exactly are these infrastructure decisions? What trade-offs are being made in popular end-to-end frameworks like Mujoco Lab, Isaac, Behavior-1K, and ManiSkill (my own). This blog series explores these decisions and their impact on everything from reinforcement learning performance to developer productivity.
Decisions and Trade-offs in the Robotics Simulation Infrastructure Stack
A good end-to-end robotics simulation framework generally provides support for end-to-end workflows, the most common in my research being simulation reinforcement learning and policy evaluations. A framework will generally have at minimum the following high-level components
Tasks and APIs (making and using environments)
Asset Management (building things in environments)
Physics Engine (the actual simulation)
Rendering Engine (seeing what is happening)
Visualization (analyze what we are seeing)
Machine Learning (training autonomous models)
A significant amount of effort also goes into making the intersection of simulation and machine learning work effectively. I spend a lot of time thinking about how to both improve machine learning performance as well as enable others’ work and research. At each step of the way one has to balance a multitude of factors like performance, development speed, and more.
For example, when it comes to asset management, multiple different simulation frameworks have massively different ways of defining a cube. Approaches range from highly config-driven (Isaac Lab: less flexible, more structured) to more direct Python-based APIs (ManiSkill/Mujoco Lab: more flexible, less structured). Both have a variety of different pros and cons on a multitude of dimensions from environment serialization to hackability.

Additionally, there is a non-exhaustive list of other questions you can be asking for each part of the tech stack (many of which deserve their own dedicated posts), for example:
Tasks and APIs: How do we simplify scene building so that a beginner (or LLM) can make a scene and easily parallelize it?
Rendering Engine: What fidelity of rendering is truly necessary? Do we need ray-tracing or is something simpler sufficient for testing our hypotheses?
Visualizer: How do we show a user what is happening beyond just what the physics engine is doing?
Some of these questions have nice solutions. Some require more trade-offs.
For visualizer tooling, Mujoco Lab does an excellent job in visualizing just about all that you need for reinforcement learning work, no more no less (and if you want more, the visualizer is easily customizable thanks to the Viser framework that powers it). For example reward curves are displayed along the visualizer in addition to allowing you to pause and visualize any previous simulation state.
For rendering, ManiSkill / SAPIEN made an early decision to focus more on performance and reducing GPU memory usage in the batched rendering system. Lower GPU memory usage leaves more memory available for RL training. GPU memory spent on larger batch sizes, replay buffers, and networks for algorithms like PPO and SAC often improve sample efficiency and thus training time/performance. This trades off the possibility for the higher-fidelity batched rendering support that Isaac Lab provides for higher rendering performance. With this decision, projects like Squint can quite train a $100 robot arm to perform various manipulation skills via zero-shot sim-to-real in minutes.
The rest of the posts in this series will cover a range of decisions made in different libraries. To keep this post shorter, in the next section I cover a very simple design decisions on API design for pose data.
A very simple example of better API design: Poses
One of the most impactful aspects of simulation infrastructure design is API design. Good API design makes infrastructure easier to maintain, and makes the codebase more accessible to new users. The best designs will make your code feel lighter.
A common example I often talk about revolves around managing 3D positions and quaternions (a common rotation representation used in robotics) representing a pose. Pose management involves two parts, storing pose data, and manipulating pose data (e.g. pose transformations).
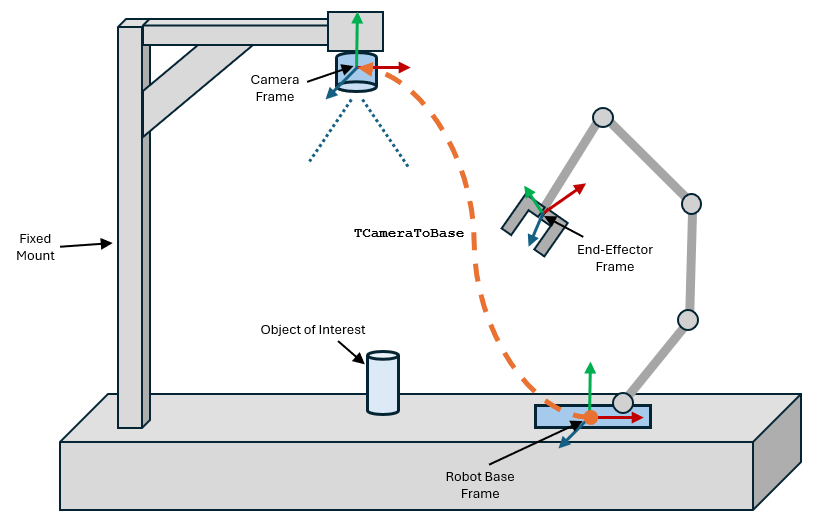
There are two primary ways to store pose data, as a single object, or two separate tensors. The post will share many code snippets, which are simplified for brevity (removing most comments and unrelated functions)
In Isaac Lab, snippets like below are common for storing references to pose data
# fetching end effector pose data in Isaac Lab
eef_pos = self.robot_asset.data.body_pos_w[env_ids, self.eef_idx]
eef_quat = self.robot_asset.data.body_quat_w[env_ids, self.eef_idx] In ManiSkill, an entire dataclass is dedicated to pose management
@dataclass
class Pose:
raw_pose: torch.Tensor
@property
def p(self):
return self.raw_pose[..., :3]
@property
def q(self):
return self.raw_pose[..., 3:]
# pose.p, pose.q give you the position and quaternions nowThe dataclass approach is slightly easier to reason about (especially if you like object oriented programming). There is just the small trade-off of python overhead with this one level of indirection via a dataclass. However, the advantages become more clear once we consider common pose operations.
A good example is computing differences between poses (often used for e.g. a reward function). The snippet below is a functional approach from Isaac Lab used in some of their environments:
def compute_pose_error(
t01: torch.Tensor,
q01: torch.Tensor,
t02: torch.Tensor,
q02: torch.Tensor,
) -> tuple[torch.Tensor, torch.Tensor]:
source_quat_norm = quat_mul(q01, quat_conjugate(q01))[:, 0]
source_quat_inv = quat_conjugate(q01) / source_quat_norm.unsqueeze(-1)
quat_error = quat_mul(q02, source_quat_inv)
pos_error = t02 - t01
return pos_error, quat_errorThe equivalent ManiSkill code is object-oriented, reads almost like mathematical notation, and is substantially easier to follow.
def compute_pose_error(
pose_01: Pose,
pose_02: Pose,
) -> tuple[torch.Tensor, torch.Tensor]
quat_error = (pose_02 * pose_01.inv()).q # P2 x (P1^-1), method chaining!
pos_error = pose_02.p - pose_01.p
return pos_error, quat_errorFewer input variables (two instead of four) and method chaining makes ManiSkill’s code easier to maintain and understand. Supporting these operations primarily involves moving the functions that Isaac Lab defines (e.g. quat_mul, quat_conjugate) into the Pose dataclass. Additionally, a less obvious benefit is that the dataclass approach for poses will remove a line or two of imports allocated for modules that contain the pose operations. When there are hundreds of different kind of objects and operations in a simulator, those lines really add up and it is far better to stick some functions behind type-hinted classes instead of modules that you need to be aware of.
Another advantage of the object-oriented approach is support for heterogeneous pose inputs. This is particularly useful for pose data because you may often use libraries that give you pose data in different formats. Perhaps you are loading some dataset with numpy or the simulator’s tensor backend is in torch/jax. An example of how ManiSkill handles this is in here, permitting code below to all return a Pose object.
Pose.create(numpy_pose), Pose.create(tensor_pose), Pose.create(sapien.Pose())Such an approach is widely adopted by plenty of other libraries like numpy which lets you create arrays by passing in plenty of different types like tuples and lists. You can take this one step further by making dataclasses for the position and quaternion data separately since there are plenty of quaternion only operations.
Every little bit of better API design helps offload your cognition, freeing up head space to focus on actual work instead of trying to understand one too many nested function calls.
Simulation infrastructure is as much a design problem as it is a technical one, and many of these decisions and trade-offs don’t appear in papers but instead live deep inside large simulation codebases. I plan to unpack some of the great innovations and designs behind some popular robotics simulation frameworks in my series. Luckily there is no shortage of robotics simulators out there
